簡單操作 Facebook 爬蟲:Facebook scraper 套件介紹
Facebook 時常改版、限制多,要找到一個適合、好用且簡單上手的工具相當困難,否則就要自己寫龐大的程式爬蟲。本篇介紹簡單好用的 facebook-scraper 套件幫助你順利爬蟲。
話說在前頭,臉書爬蟲過於頻繁,此爬蟲方式極大可能帳號會被ban,當然進行簡單的認證可能又可以恢復,但請仍注意友善爬蟲。爬蟲對於架站網頁伺服器仍有一定負擔,請務必注意注意!
因為擔任研究助理需求,需要嘗試找尋 Facebook 爬蟲的工具,現有較為快速、合理且有效的方式包含使用官方 Graph API 及 CrowdTangle 服務,然而前者目前筆者難以找到快速、免費的申請方案,後者筆者曾經使用過,雖然可以快速爬下所有粉專內容、抓取各時段貼文,但仍舊需要付費或學術用途(但真的很好用QQQQ,且省事非常非常非常多)。
後來在網路上找到一個python的套件 facebook-scraper,使用起來相對上手且簡單,雖然仍有諸多缺失,但仍能堪用,因此撰文簡單介紹。
其實該套件提供的 Github 頁面已然相當完整,也可以多利用 Discussion 頁面找尋在操作上面臨的狀況與問題。
facebook-scraper 似乎是基於 selenium 對於動態頁面向下捲動的原理,進行一頁一頁爬蟲。此套件仍存在一定的限制,下方將介紹一些使用心得與使用方法,供後人參考。
facebook-scraper 的優缺點
優點
- 無需 API key
- Python 套件,容易上手。Github 文件完整。
- 回傳 json 資料,易於處理。
- 相較於 CrowdTangle(另一個付費社群資料庫系統),facebook-scraper 還可以取得部分留言資料。
缺點
- 仍須從自己的臉書帳戶將 cookie 文件載下,因此在操作過程中若過於頻繁抓取資料,可能遭到臉書封鎖你的帳號(但可以再操作打開)。
- 有時候在操作過程中可能遭到臉書封鎖(但並未直接封鎖帳號),因此雖程式仍持續進行爬蟲,但並沒有資料回傳,這時候可能就需要稍等一陣子(數小時~數天)再行爬蟲,可以有所改善。
- cookie 檔案需按時更新。
- 僅能從進行爬蟲的「此時此刻開始向前爬蟲」,無法設定特定日期與時間爬蟲。
前期準備
一組 cookie
何謂 cookie?可以先簡單理解為,當我們進入個人臉書時,需要一組正確的帳號、密碼,在網頁背後的邏輯當中,就像是取得一把鑰匙,讓使用者可以自由在自己的頁面底下觀看貼文。
而我們這邊要取得的 cookie,就是希望直接取得這把鑰匙,提供程式爬蟲時自由進出頁面取得對應的貼文內容與相關資訊。
官方文件中提供多種下載 cookie 方式,筆者使用chrome 外掛套件「Get cookies.txt」。登入臉書帳號後,停留在自己的臉書頁面塗鴉牆,點選 chrome 外掛,按下「Export As」輸出cookie 檔案備用。
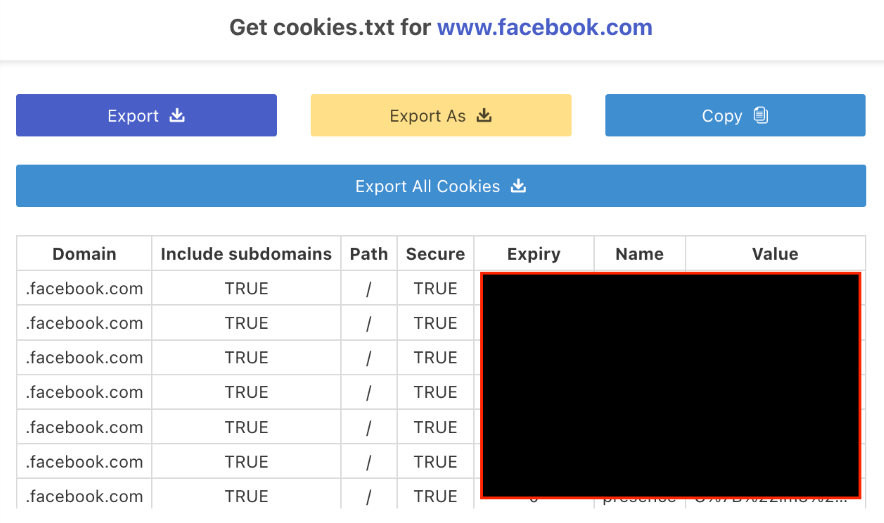
切記,這個cookie是有時間限制的,因此每新爬蟲一個粉專,建議重新取得一次cookie檔案。
需要爬蟲的臉書粉專或臉書社團
需要準備一個需要爬蟲的臉書粉專或社團(社團我沒有使用過),並取得 user id。
這裡所謂的 user id 如何取得?舉例而言,如果今天想要抓前台北市副市長黃珊珊的臉書頁面,可以先到她的粉專,並觀察網址:「https://www.facebook.com/taipei33 」。所謂 user id,就是網址後面的尾綴「taipei33」,其他粉專也可以依樣畫葫蘆。
不過有些粉專沒有明確 user id,也可以使用「數字」,舉例而言,「花蓮縣平森永續發展協會」的臉書粉專網址為「https://www.facebook.com/profile.php?id=100069007975488 」,因此,若要取得 user id,也可以使用「100069007975488」,根據個人經驗是有機會抓取到的。
接著,你需要選擇一個爬蟲時段,如同上文所述,facebook-scraper需要從此時此刻往回爬蟲。根據經驗,facebook-scraper若進行過於長時間的爬蟲(超過半年),很可能就會開始掉資訊(最常遺失的資訊像是按讚數、留言數、分享數),因此使用前仍需評估確認。
facebook-scraper 使用
使用 CLI 下指令
(以下以mac/linux為例)
打開終端機,將facebook-scraper依下方指令下載到本機端。
(註記一下,下方的$是不用輸入的,只要打後方指令到終端機喔!)
1 | $ pip install facebook-scraper |
下載後,即可使用下方指令下載文件:
1 | $ facebook-scraper --filename 下載檔名稱.csv --pages 要爬幾頁 粉專名稱 |
舉例:
1 | $ facebook-scraper --filename taipei33.csv --pages 10 taipei33 |
其中,上面的「10」就是代表捲動頁數,但到底一頁是幾篇貼文,似乎也不一定。
此外,一些參數也可以幫助您在爬蟲時更加順利。「-v」可以將錯誤訊息輸出在畫面上、「-s」可以設定每則貼文中間的睡覺時間(強烈建議設定)、「-c」後面可以加上cookie文件。
官方說明如下:
1 | -v, --verbose Enable logging |
因此,如果是我,我會這樣下指令:
1 | $ facebook-scraper --filename taipei33.csv --pages 500 taipei33 -v -s 200 -c ../cookies/facebook.com_cookies_12.txt |
不過這個方法有個缺失,就是無法設定截止時間,因此如果是我,我會先設定長一點的捲動頁面數,然後事後再做資料清理。
直接使用 python facebook-scraper 套件
直接寫python code,就沒有上述無法設定截止時間的問題。可以直接設定條件判斷
同樣透過 pip 下載過後,即可開始使用。基本上,官方文件有提供facebook-scraper回傳的格式,然而,您也可以透過您的需求選擇想要的欄位。
其中,「option」提供多種抓取模式,我所用過的包含「options={"comments": True}」取得留言資料(預設不會取得留言);「options={"reactors": True}」取得貼文表情(預設僅顯示讚數)。
不過依照個人經驗,很可能因為爬蟲時間長,貼文表情沒有順利取到;爬留言的話,也僅能抓到最相關的三十則留言,及這些留言的回覆(replies)。因此建議如果可以的話,簡單就好(reactor 設定 false、comments 也設定 false)。
下方提供我寫的程式碼供參考(官方也有提供),其中我有特定選幾個我想要的欄位,但可能因為爬蟲過程中部分欄位會顯示None或空值導致報錯,因此如果要使用的朋友,請依照自己的需求去補撰寫一些code:
1 | P = pd.DataFrame() |